COCO Dataset은 Object Detection, Segmentation, Keypoint Detection 등을 위한 데이터셋으로, 매년 전 세계의 여러 대학과 기업이 참가하는 대회에서 사용되고 있다. COCO Dataset 자체를 이용하기도 하지만, 데이터를 저장하는 방식인 COCO Data format 역시 많이 활용되기도 한다. COCO Data format과, 이를 불러오고 사용할 때 유용한 COCO API인 Pycocotools에 대해 알아보자.
COCO Data Format
Detection, Segmentation 등 태스크를 위해서는 bounding box의 좌표, segmentation mask 픽셀 등 필요한 정보가 많다. 따라서 이러한 정보들(annotation)을 json 형태로 제공한다.
+ Dictionary와 JSON의 차이점?
:그것은 마치 사과와 오렌지를 비교하는 것과 같다! JSON은 데이터 포맷이고, Dictionary는 Python의 데이터 구조 (자료구조)이다. 따라서 Dictionary 데이터를 JSON 포맷으로 이용하기 위해서는 Serialization(직렬화, 객체를 바이트 스트림으로 바꾸는 과정)이 필요하다.
출처: stackoverflow.com/questions/33169404/whats-the-difference-between-python-dictionary-and-json
JSON 파일은 Info, Licences, Images, Categories, Annotations, 크게 5가지로 구분된 정보를 담고 있다.
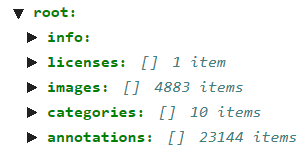
1) Info
Info는 데이터셋에 대한 데이터셋 버전, 설명, 생성 날짜 등 high-level한 정보를 포함하고 있다.

2) Licences
이미지의 라이센스 목록이 포함되어 있다.

3) Images
데이터셋에 속하는 전체 이미지 목록과 같다. 이미지 각각의 파일명, width, height 등의 정보가 포함되어 있다.

4) Categories
데이터셋에 존재하는 Category에 대한 정보(id, name)가 담겨 있다.

5) Annotations
한 이미지에는 여러 객체가 존재할 수 있기 때문에, Annotation은 이미지가 아닌 객체를 기준으로 작성되어 있다. json 파일을 annotations 변수에 불러왔다고 가정했을 때, annotations ['Images']는 이미지 id당 한 개의 dict만 존재하지만, annoatations['annotations']는 이미지 id 당 여러 개(= 해당 이미지에 담긴 객체 수만큼의 dict가 존재한다.
아래 예시를 보면 하나의 image_id지만 각기 다른 object에 대한 정보를 담고 있다.
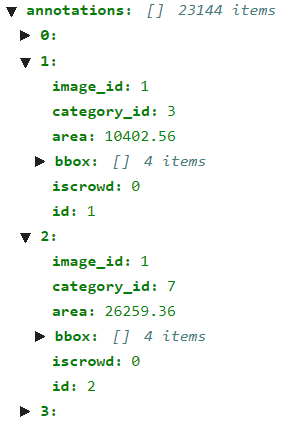
(1) image_id
해당 annotation이 어떤 image에 속하는지를 가리킨다.
(2) category_id
해당 annotation의 object가 어떤 카테고리에 속하는지를 가리킨다. 이 숫자 각각이 어떤 것을 의미하는지는 4) Categories의 정보로 확인할 수 있다.
(3) segmentation
각 class에 해당하는 pixel의 x, y 좌표가 포함되어 있다.
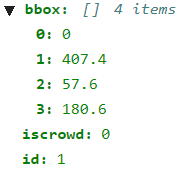
(4) bboxObject detection
태스크를 위한 bouding box 정보로, 순서대로 좌측 상단 지점의 (x, y) 좌표, width, height를 의미한다. 이외에도 iscrowd, id 데이터가 포함되어 있다.
Pycocotools
위 json 파일에서 우리가 주로 이용하게 될 데이터는 Images와 Annotations인데, 정보가 흩어져 있기 때문에 두 정보를 잘 join해 활용할 수 있어야 할 듯하다. 또한 데이터 EDA, 시각화 등을 위해서는 한 Image에 속하는 모든 annotation을 불러오는 코드 등도 있으면 좋을 것 같다. 바로 이러한 작업들을 수월하게 해주는 API가 바로 Pycocotools이다. Pycocotools의 여러 class 중에서 COCO class에 대해서 알아보자. 코드 읽는데 어려움이 없다면 공식 github에서 직접 확인해보는 것도 좋을 것 같다.
1) 불러오기
COCO 클래스를 불러오는 방법은 아주 간단하다. pycocotools 패키지에서 import 해온 뒤, json 파일 주소와 함께 선언해주면 된다.
from pycocotools.coco import COCO
coco = COCO('../dataset/train.json')2) getAnnIds
Image id, Category id를 input으로, 그에 해당하는 annotation id를 return 하는 함수이다.
# 0번 image에 해당하는 Annotations id
print(coco.getAnnIds(ImgIds=0))# Category 9에 속하는 Annotations id
print(coco.getAnnids(catIds=9)3) getCatIds
Category 이름, Super Category 이름을 input으로, 그에 해당하는 Category id를 return하는 함수이다.
print(coco.getCatIds(supNums='Battery')4) getImgIds
Img id, Category id를 input으로, 그에 해당하는 Image id를 return하는 함수이다. getAnnIds의 Image 버전이라고 생각하시면 될 것 같다.
print(coco.getImgIds(catIds=9)5) loadAnns
Annotation id를 input으로 annotation dict 전체를 return하는 함수이다.
print(coco.loadAnns(3))6) loadCats
Category id를 input으로 Category name, super category 정보가 담긴 dict를 return하는 함수이다.
print(coco.loadCats(3))7) loadImgs
Image id를 input으로 annotations의 image dict를 return하는 함수이다.
print(coco.loadImgs(0))
"""
[{
'width':1024,
'height':1024,
'file_name':"train/0000.jpg",
'license':0,
'flickr_url':null,
'coco_url':null,
'date_captured':"2020-12-26 14:44:23",
'id':0
}]
참고: https://comlini8-8.tistory.com/67,
https://ukayzm.github.io/cocodataset/
'Python > PyTorch' 카테고리의 다른 글
| [Pytorch] 모델 저장하고 불러오기 (0) | 2021.09.28 |
|---|---|
| [Pytorch] 모델 매개변수 최적화하기 (0) | 2021.09.28 |
| [Pytorch] TORCH.AUTOGRAD를 사용한 자동 미분 (0) | 2021.09.26 |
| [Pytorch] 신경망 모델 구성하기 (0) | 2021.09.25 |
| [Pytorch] Transform (0) | 2021.09.25 |
