Optimization 알고리즘은 신경망 모델이 빠르게 학습할 수 있게 한다.
Loss function을 통해 구한 차이를 사용해 기울기를 구하고 네트워크의 parameter인 W와 b의 학습에 어떻게 반영할 것인지를 결정하는 방법이다.
1. Gradient Descent Algorithm
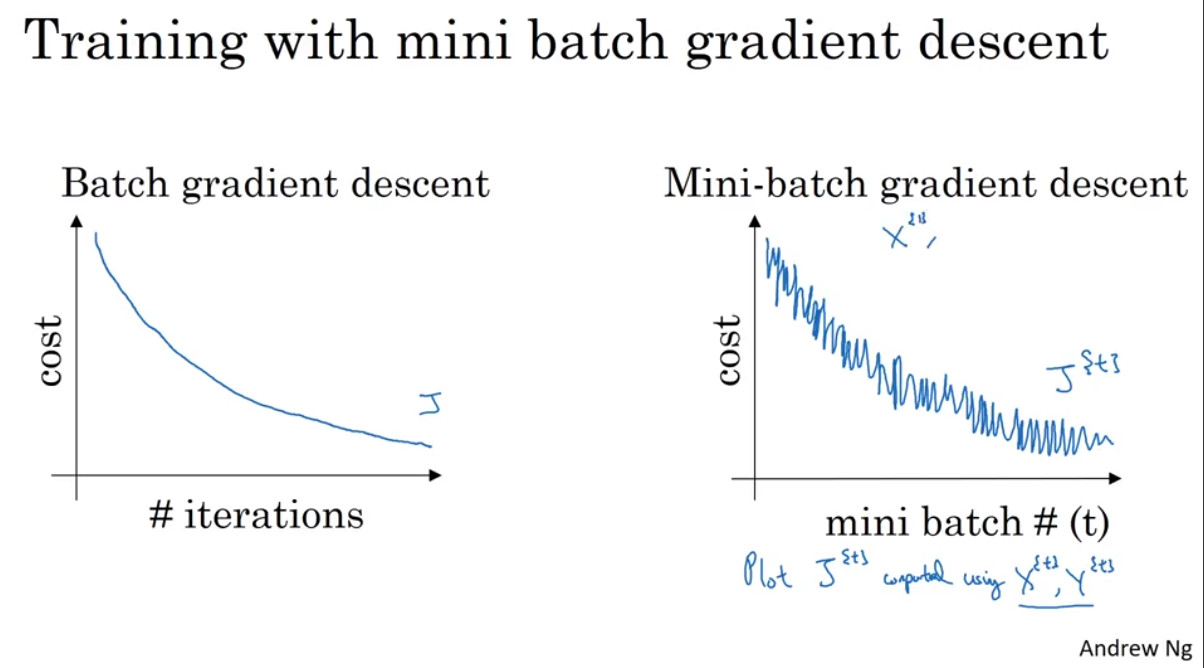
Batch Gradient Descent (BGD)
batch는 모든 data를 의미한다.
즉, 모든 데이터를 한꺼번에 계산해서 weight와 bias를 얻는 방법이다.
따라서 매끈하게 cost함숫값이 줄어든다.
한 step에 모든 학습 데이터를 사용해서 학습이 오래 걸린다는 단점이 있다.
Mini-batch Gradient Descent (MGD)
전체 데이터셋을 여러 개의 mini-batch로 나누어 한 개의 mini-batch마다 기울기를 구하고 모델을 업데이트하는 방법이다.
일반적으로 mini batch로 잘라서 실행하면 train data하나하나에 대해서 즉시 gradient가 계산돼서 weight와 bias가 업데이트되므로 훨씬 더 정교하게 움직일 수 있다.
데이터의 일부분만 GPU에 올려서 계산하므로 수렴 속도가 빨라질 수 있다.
Stochastic Gradient Descent (SGD)
mini batch size가 1인 Mini-batch Gradient Descent라고 생각하면 된다.
데이터를 하나씩 처리하기 때문에 벡터화 과정에서 속도가 매우 느리다는 단점이 있다.
Mini-batch size 정하는 방법
일반적으로 딥러닝 서버에 올릴 수 있는 CPU/GPU의 메모리의 양을 보고 한번에 올릴 수 있는 양만큼으로 mini-batch를 만드는 것이 좋다.
training set이 작다면 batch gradient descent을 이용하고
아니라면 메모리의 size가 2의 n승이므로 2의n승의 숫자로 mini-batch size를 갖는 mini-batch gradient descent를 이용한다.
2. Momemntum
Exponentially Weighted Averages(지수 가중 평균)
Momentum알고리즘을 이해하기 위해서는 Exponentially Weighted Average(지수 가중 평균)을 이해해야 한다.
Exponentially Weighted Averages란 데이터의 이동 평균을 구할 때, 오래된 데이터가 미치는 영향을 지수적으로 감쇠하도록 만들어주는 방법이다.
런던의 일일 평균 날씨에 관한 데이터를 살펴보자.

이 데이터의 트랜드를 산출하기 위해서는 어떻게 해야 할까?
단순히 전후 몇일간의 평균으로만 계산한다면 오래된 데이터의 영향과 최신 데이터의 영향이 비슷해져서 우리가 원하는 추세를 나타낼 수 없을 것이다.
이를 보완하기 위해 시간이 흐름에 따라 지수적으로 감쇠하도록 설계하는 지수 가중 평균이 도입되었다.
일단
![]()
으로 초기값을 설정해 준다.
다음으로, 일 별로 모든 값을 평균화 한다.

v라는 날에 대한 공식의 일반화는 0.9*(이전 날짜 v) + 0.1*(그날의 온도) 이다.

위 그래프의 빨간색 선이 지수 가중 평균으로 구한 일별 날짜의 온도의 이동편균으로 나타낸 그래프이다.
지수 가중 평균식은 다음과 같다.

(0 <= β <= 1, θ: 새로운 데이터, v: 현재의 경향)
지수 가중 평균식은 또한 다음과 같이 나타낼 수 있다.

vt-2앞에 0~1사이의 beta값이 곱해지므로, 오래된 데이터일수록 현재의 경향에 미치는 영향이 줄어든다는 것을 알 수 있다.
예전 데이터는 β^n으로 지수적을 빠르게 감소하므로 지수적 감쇠(exponentially decay)라고 부른다.
지수 가중 평균의 근사
지수 가중 평균은 1/(1-β)일의 데이터의 평균을 사용하여 근사한다.
예를들어
이면, 이전 10일의 온도의 평균이 그날의 이고(빨간색 그래프)
이면, 이전 50일의 온도의 평균이 그날의 이고(초록색그래프)
이면, 이전 2일의 온도의 평균이 그날의 입니다.(노란색 그래프)


- 의 경우 오늘의 기온은 더 적게 반영되고 그 전 기온은 더 많이 반영된다. 값이 1에 가까워, 많은 날을 고려하기 때문에 noise가 없고 더 부드러운 그래프 모양이 나온다. 또한 더 큰 범위의 온도로 평균치를 구하기 때문에 그래프가 오른쪽으로 이동하였다.
이 경우, 이전 데이터에 의 큰 가중을 적용하고, 현재 데이터에 라는 작은 가중을 적용한다. 최신 데이터보다는 과거의 데이터에 대한 비중이 크다. - 의 경우 훨씬 더 작은 범위의 평규치를 구하게 된다. 데이터가 더 noisy하고, 이상점에서 훨씬 취약하게 된다. 하지만, 기온변화를 빠르게 반영한다.
Bias Correction
지수 가중 평균을 이용한 추정은 초기 구간에 오차가 있다.
머신러닝에서는 지수 가중 평균을 구현할 때 초기 구간을 기다린 후 사용하기 때문에 바이어스 보정을 신경쓰지 않는다.
하지만, 초기 구간의 바이어스를 신경쓴다면 바이어스 보정을 사용해야 한다. 바이어스 보정은, 기존에서 를 나누어 주면 된다.
Gradient descent with Momentum
이전 step의 방향(=관성)과 현재 상태의 gradient를 더해 현재 학습할 방향과 크기를 정하는 방법이다.
Local minima를 빠져 나올 수 있으며 SGD의 Oscilation 현상이 해결 가능하다.
standard gradient descent보다 더 빠르게 작동된다.
수식은 다음과 같다.

gradient값에 exponentially weighted average값을 계산해서 업데이트 해준다.
RMSProp (Root Mean Square Propagation)
학습이 오래 진행되면 step size가 너무 작아지는 adagrad의 단점을 보완하기 위한 방법이다.
각 변수에 대한 gradient의 제곱을 계속 더하는 것이 아니라, 지수평균으로 바꾸어 G값이 무한정 커지지 않도록 방지하면서 변화량의 상대적인 크기 차이를 유지한다.

Adaptive Moment Estimation (Adam)
Momentum 방식과 유사하게 지금까지 계산해온 기울기의 지수평균을 저장한다.
RMSProp 와 유사하게 지금까지 계산해온 기울기의 제곱값의 지수평균을 저장한다.
학습 초반부에 m과 v가 0에 가깝게 bias되어 있을 것이라고 판단해 unbiased 작업을 거친 후에 계산한다.

3. Adagrad (Adaptive Gradient)
Parameter 별로 gradient 를 다르게 주는 방법이다.
많이 변화한 변수들은 G에 저장된 값이 커지기 때문에 step size가 작은 상태로, 적게 변화한 변수들은 상대적으로 step size가 큰 상태로 학습에 반영한다.
학습이 오래 진행되는 경우 G값이 너무 커져서 학습이 제대로 되지 않는다

참고: velog.io/@minjung-s/Optimization-Algorithm
'🤖AI > 딥러닝' 카테고리의 다른 글
| [딥러닝] RNN (0) | 2021.05.25 |
|---|---|
| [딥러닝] CNN (Convolution Neural Network) (0) | 2021.05.15 |
| [딥러닝] Overfitting을 완화시키는 방법(2) - Dropout (0) | 2021.04.15 |
| [딥러닝] Overfitting을 완화시키는 방법(1) - Regularization (0) | 2021.04.15 |
| [딥러닝] Bias와 Variance (0) | 2021.04.13 |


